












Introducing SafeHop: Maximize uptime and reduce origin errors by up to 80% with origin retry

Dejan Grofelnik Pelzel

November 9, 2021
Let's face it, things sometimes fail. Servers fail, networks fail, software fails... DNS fails. It's a natural process that we can't work around. What we can do however, is control such failures. Just because a part of a system failed, it shouldn't mean that the whole system should fail as a result. Controlling sub-system failure should be as important if not more important than preventing it.
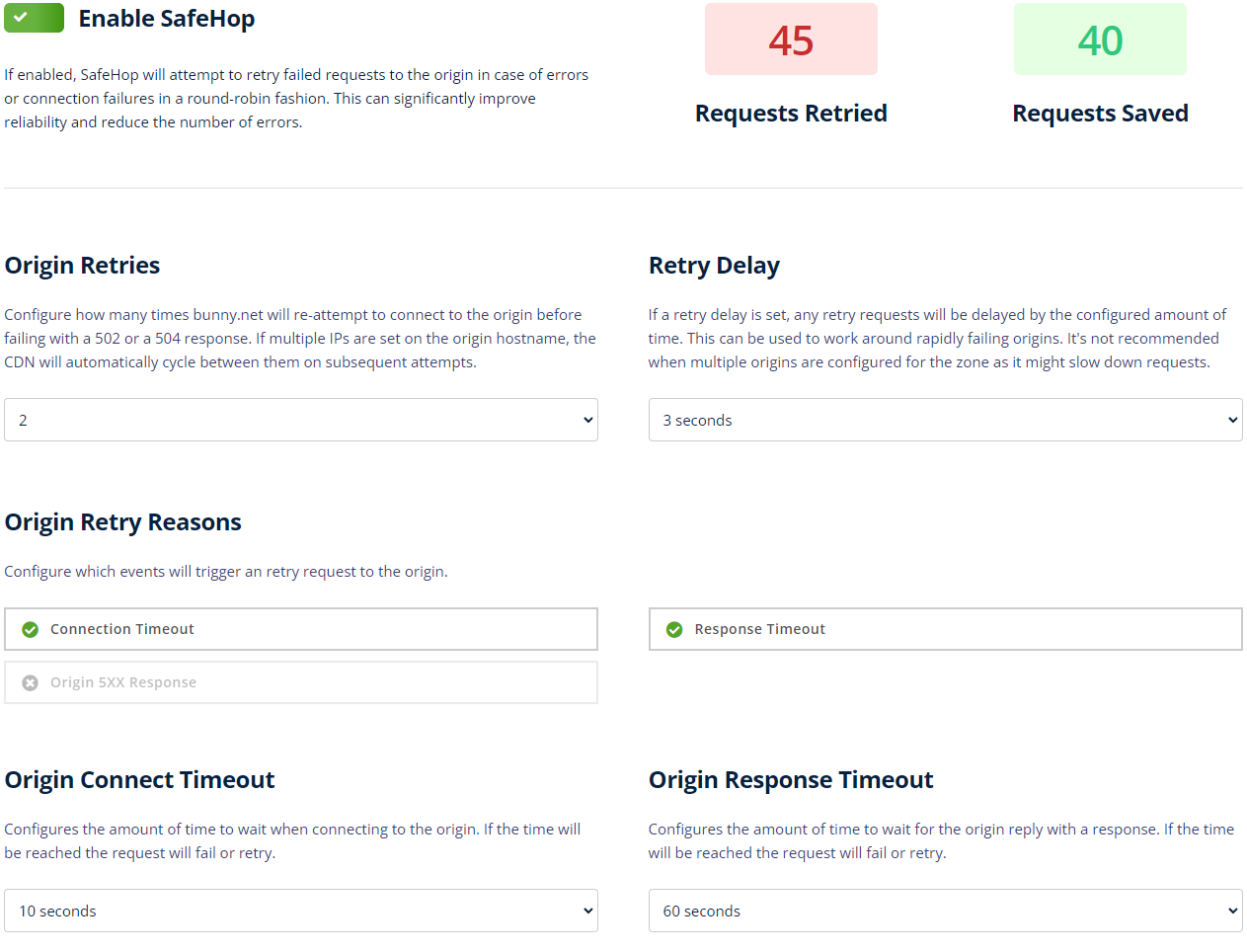
Today, we are excited to announce SafeHop, a new system designed to reduce origin errors and maximize uptime by adding origin request retrying. SafeHop allows you to easily configure timeouts, delays and request retries to your origin to work around any potential network issues.
Initially, we developed this system to re-route failed requests with our Edge Storage, but after seeing great results, we knew we had to bring this to everyone. It was our goal to not only control failure, but work around it and allow our users to lower error rates and achieve the highest uptime possible. During our testing, we saw up to 80% reduction in origin error rates and greatly improved reliability through potential software restarts and we're happy that we are able to bring this system to all of our users.
The system is now live for all of our users and available with just a click of a button!
Smart Origin System
If your origin is configured with multiple IPs, SmartHop will automatically attempt to retry between different addresses and intelligently learn which one to prioritize in case of errors. If you have a single IP on the other hand, we will simply retry that one as configured.
Survive Restarts With Retry Delay
So what does a failure mean? In our experience, it can be something as simple as a software restart or a temporary hiccup. When software is restarted or killed, retrying the connection would not be all that beneficial since subsequent requests would simply fail in a rapid succession.
To work around this, we designed a delay system. By adding a delay between subsequent retry requests, we can wait for the origin to come back online. While this is not ideal from a performance perspective, it can mean a difference between a failed and a successful request. In the end, a response is better than no response.
Configurable Timeouts
To handle efficient retrying, we are also introducing new configurable timeout settings. With these, you can control how long bunny.net will wait for a response before trying again or moving to the next server. The new timeout configurations however also work by themselves. If origin retrying is not your thing, you can use the new settings to control how long bunny.net will wait for a reply from your origin before giving up and even fail faster if needed.
In the future, we also aim to offer increased timeouts for responses longer than 60 seconds for cases where long running requests might be expected.
Powering an Internet That (Always) Hops
As bunny.net is quickly approaching 1 million powered websites, we're excited about the benefits this will bring for the internet and empowered to continue improving and innovating to make the internet hop faster, or in this case hop at all.
If you enjoy innovation, working on next-generation cloud technologies and would like to drive a mission of helping build a faster internet, check out our careers page!