
The magic behind Magic Containers: how we use AI to lower your costs while maximizing performance

Dejan Grofelnik Pelzel

March 26, 2025
Edge computing was supposed to be the future. Ultra-low latency, distributed applications, seamless global scaling. But if you've ever deployed a busy, complex application to the edge, you've probably run into a not-so-magical reality: it's expensive. Like, really expensive.
When we built Magic Containers, we didn’t want to build just another platform that sells you on these promises. We wanted to rethink edge computing as a whole and tackle one of its biggest problems: the excruciating cost.
The edge-old problem: it’s a race to everywhere, at any cost
What was meant to solve the problem of application latency by deploying distributed applications globally quickly evolved into a race to see who could build out the biggest number of edge regions. However, while this might sound exciting from a marketing perspective, it can quickly turn into a horror story of unexpected costs.
This is especially true for heavyweight applications that need to run continually and require sizable amounts of processing power. One instance here, two more there, and you’re quickly running with a hundred replicas of your application around the world. Even if the actual latency impact is barely noticeable.
When a single deployment costs you $100 per month to run, and the latency between Ashburn, Pittsburgh, or New York is less than 3 ms, does it really make sense to provision three separate instances of your application? In most cases, the answer is a simple no. A home Wi-Fi network can easily add more latency than this.

Some companies tried to address this by dynamically provisioning your application and killing it as soon as it’s no longer needed. While this works fantastically for simple, lightweight applications that can cost just cents to run, even this approach still comes with a catch.
If it takes more than 3 ms to start up the app, and there’s a perfectly fine instance already running nearby, you’ve already lost all the benefits of running closer in the first place.
Even if the startup time is as little as 10 ms, which seems extremely low for any application that doesn't just respond with a static response, it might still be significantly faster to simply send a request 2 ms further to a region where the application is already alive.

Where this approach really crumbles is when you try to apply the same routing and provisioning logic to run complex, heavy applications that can't just start up and down in miliseconds. That’s simply a disaster waiting to happen. With edge networks boasting up to 50+ regions within the US alone, if you’re not careful, you might quickly run into a six-figure monthly bill.
The edge how it should be: smarter, not wider
We believe this problem alone is one of the biggest hurdles of computing at the edge, and with Magic Containers, we aimed to find a better way.
While we’re equally excited about continually expanding our massive global network, we believe edge computing is not just about going wider and wider. We believe the answer is in making it smarter.
To really understand where the issue lies, it’s important to revisit the main goal of edge computing as a whole. Fundamentally, edge computing aims to improve performance by reducing the latency between the application and the end users.
But in most cases, as latency decreases, you will start seeing diminishing returns. Users won't notice a difference between 3 ms and 2 ms latency, but they will definitely notice the difference between 100 ms and 50 ms. This means traditional edge computing, while great on paper, is excessively over-provisioned by design.
When building Magic Containers, it was our goal to fundamentally rethink how edge compute networks operate and drastically reduce the cost of distributed global computing. We did that with the power of AI and a push to make the edge smarter, not just wider.
The magic of AI: reducing the cost of computing at the edge
Rather than immediately responding to incoming traffic, we built a machine-learning model that constantly monitors your global traffic, resource consumption, latency, and, most importantly, cost.

Since we already operate one of the fastest edge networks in the world that serves as the entry point for all Magic Containers traffic, we have complete visibility into the latency between Magic Containers applications and end users.
This allows us to feed this real-time data to an AI provisioning and scaling model that we fine-tuned with different cost and latency weights. The model is then able to make smart decisions to optimize the global deployment based on your actual traffic.
Provisioning where it matters, when it matters
Our AI model continuously analyzes traffic patterns and makes intelligent decisions about where to deploy your application. Instead of blindly deploying everywhere, it strategically places compute resources in regions that will have the most significant impact. This approach ensures you're getting the maximum performance benefit while minimizing unnecessary costs.
As your traffic shifts and changes, the model will continually optimize your deployments and gradually move them around to maintain exceptional performance for all of your users.
What this means in practice is fairly simple. If the majority of your traffic is from Europe and Asia, it makes little sense to be running 20 other active regions on different continents. Perhaps just one or two per continent would work just fine and still deliver acceptable latency, depending on your specific requirements and what works for your application at that specific time.
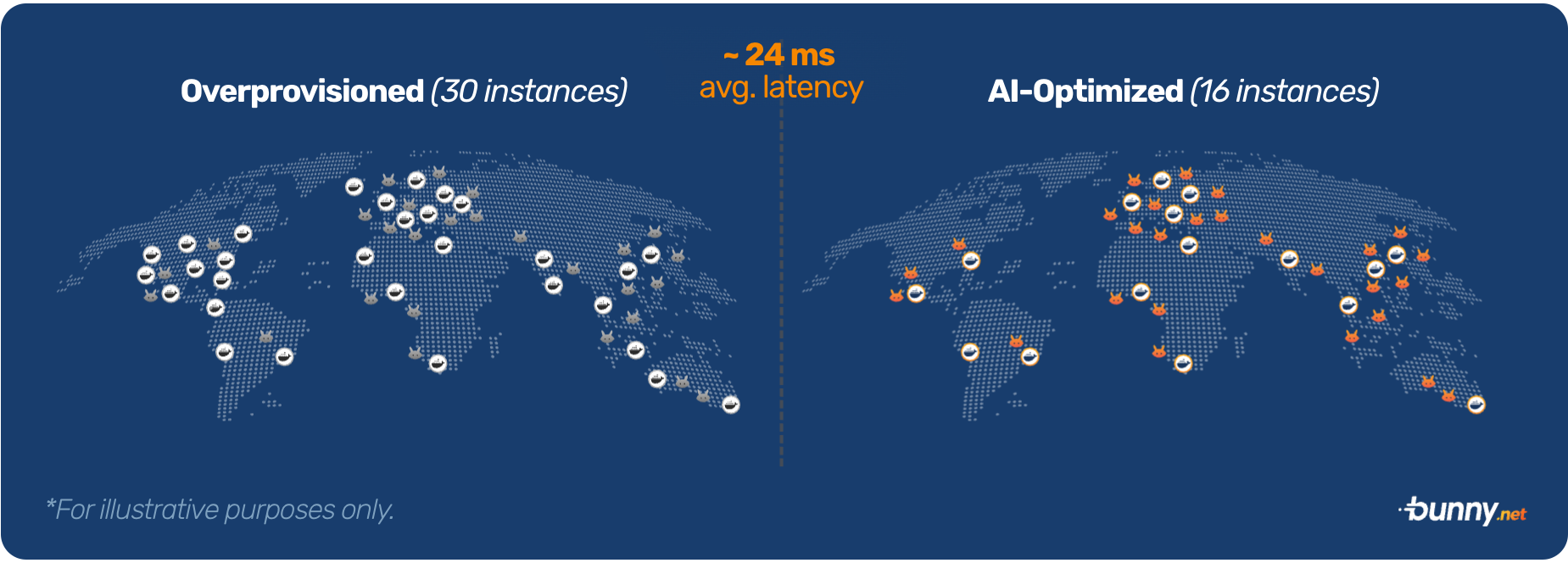
Scaling regionally, not just locally
To push efficiency even further, we combined the auto-scaling model and provisioning model into one. Instead of scaling each deployment region individually as traffic goes up, the AI model optimizes both the scaling and provisioning actions to work hand in hand and continually optimizes both efficiency and latency.
To illustrate this, let’s look at a hypothetical scenario where we’re aiming for exceptional efficiency. Let’s say 80% of your traffic comes from Germany and 20% from London. All of that is powered by 10 instances in Frankfurt.
When the CPU levels reach too high, and it’s time to add that 11th instance, traditional systems would simply scale up Frankfurt. We took it to the next level.
Magic Containers understands that by provisioning London instead, a portion of traffic will flow to the new region, reducing the load on the Frankfurt location while also improving the latency for your users from the United Kingdom. And the best part, while being as efficient as possible.
This way, we ensure any action we take, directly drives down both cost and latency, to hit your desired target.
Magic Containers does all of this automatically. Like magic.
The result: up to 5x lower costs
By automatically optimizing the deployments to run exactly where they need to, when they need to, based on your actual traffic, and combining that with true pay-as-you-go, resource-based pricing, Magic Containers is able to deliver up to 5x lower costs without sacrificing performance compared to traditional edge computing platforms.
The smart provisioning model ensures you're not paying for unused capacity while still delivering excellent performance where it matters most.
For example, in regions with high traffic volumes, the system might maintain multiple instances to handle the load efficiently. In areas with lower, more sporadic usage, it might opt for a different, more conservative deployment strategy, depending on what works best for you.
Efficiency or speed—it’s up to you
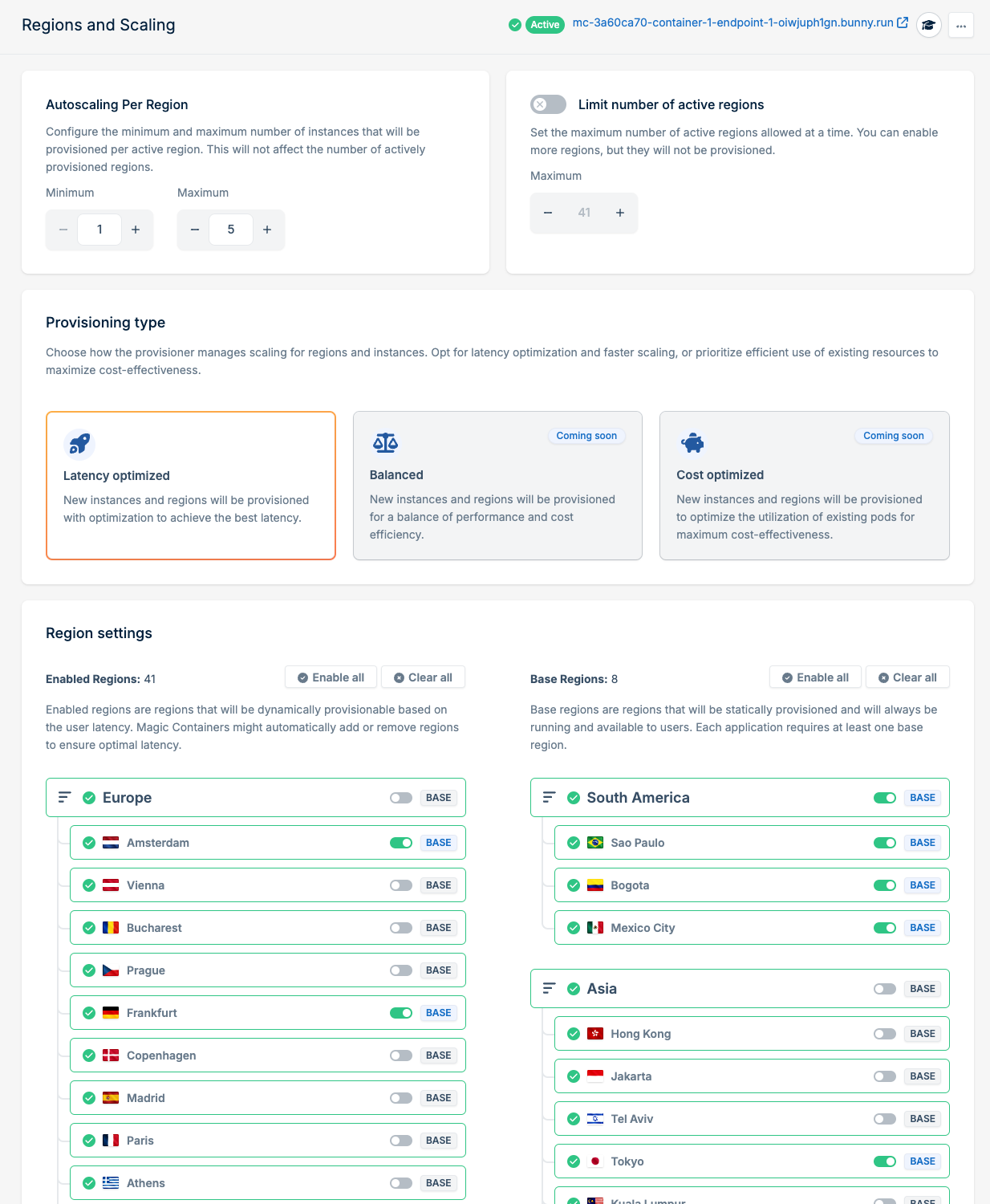
But what if I want to run everywhere? No worries. While our goal was to finally make edge computing efficient enough for anyone to use, we know each project is special. For that reason, we’re building in different provisioning types, each with a different traffic profile in mind.
Here's how each of them works in practice:
- Latency optimized: This model prioritizes ultra-low latency by maintaining presence in more edge locations. It's perfect for latency-critical applications where performance is the top priority, with less focus on cost.
- Balanced: The balanced model maintains optimal performance while being cost-conscious. It intelligently provisions resources based on traffic patterns and latency requirements, striking the perfect balance between speed and efficiency.
- Cost optimized: For the cost-conscious, the cost-optimized model will prioritize lower cost while strategically distributing the application globally, making sure you don’t overspend, while still achieving most of the benefits of distributed computing.
At launch, we started with the Latency-optimized model, and we're working to release the other two models soon.
Of course, if you have specific regions you want—or don’t want—to run in, you can configure that as well. Magic Containers gives you just as much control as you need, or as little as you want, which not only helps with performance and cost but also simplifies compliance.
Hop on and give it a try!
True to our mission, one of the reasons we built Magic Containers was to make edge computing viable for everyone, not just large enterprises. We believe AI helped us make the magic happen. Along with real, resource-based pricing, where the only thing you pay is the actual resources that you use (such as CPU time and RAM), we want to bring the magic of computing at the edge into the hands of everyone.
If you’ve struggled with high costs or over-provisioned infrastructure, make sure to check out Magic Containers. It takes only a few minutes to deploy your first application. It’s our vision to help developers and companies like yours by providing exceptional performance while tightly controlling costs when deploying globally, and we're excited to see what you take global next.