













The stack overflow of death. How we lost DNS and what we're doing to prevent this in the future.

Dejan Grofelnik Pelzel

June 23, 2021
If there was one metric at bunny.net that we obsess about more than performance, that would be reliability. We have redundant monitoring, auto-healing at multiple different levels, three redundant DNS networks and a system designed to tie all of this together and assure your services stay online.
That being said, this gets so much harder. After an almost stellar 2 year uptime, on 22nd of June, bunny.net experienced a 2+ hour near system-wide outage caused by DNS failure. In a blink of an eye, we lost over 60% of traffic, and wiped out hundreds of Gbits of throughput. Despite all of these systems being in place, a very simple update brought it all crumbling down, affecting over 750.000 websites.
To say we are disappointed would be an understatement, but we want to take this opportunity to learn, improve and build an even more robust platform. In the spirit of transparency, we also want to share what happened and what we're doing to resolve this going into future. Perhaps even help other companies learn from our mistakes.
It all started with a routine update
I will say this is somehow probably the usual story. It all started with a routine update. We are currently in the process of massive reliability and performance improvements throughout the platform and a part of that was improving the performance of our SmartEdge routing system. SmartEdge leverages a large amount of data that is periodically synced to our DNS nodes. To do this, we take advantage of our Edge Storage platform that is responsible for distributing the large database files around the world through Bunny CDN.
In an effort to reduce memory, traffic usage, and Garbage Collector allocations, we recently switched from using JSON to a binary serialization library called BinaryPack. For a few weeks, life was great, memory usage was down, GC wait time was down, CPU usage was down, until it all went down.
On June 22nd at 8:25 AM UTC, we released a new update designed to reduce the download size of the optimization database. Unfortunately, this managed to upload a corrupted file to the Edge Storage. Not a problem by itself, the DNS was designed to work either with data or without data and was designed to graciously ignore any exceptions. Or so we thought.
Turns out, the corrupted file caused the BinaryPack serialization library to immediately execute itself with a stack overflow exception, bypassing any exception handling and just exiting the process. Within minutes, our global DNS server fleet of close to a 100 servers was practically dead.
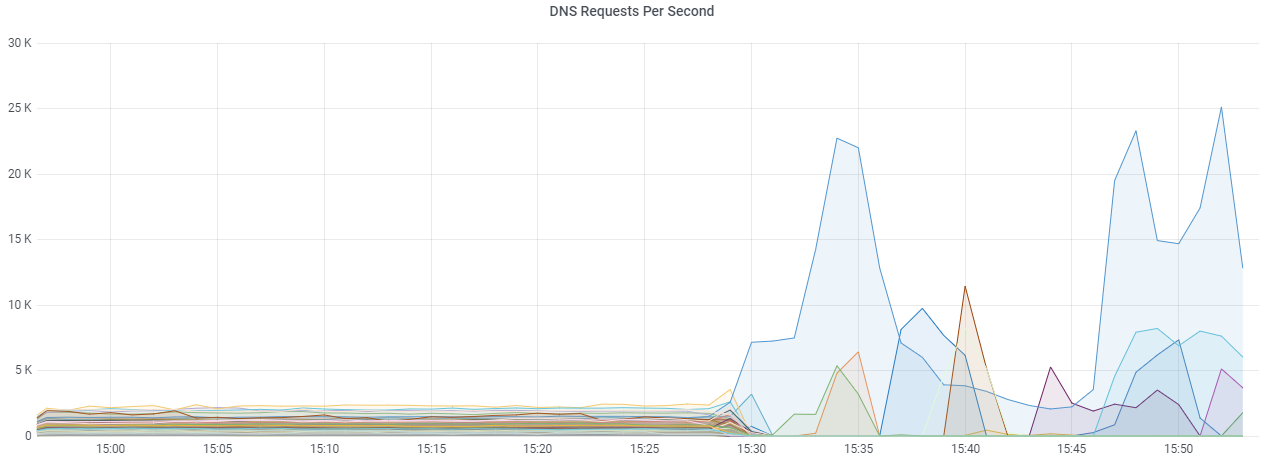
Then things got complicated
It took us some time to actually realize what was going on. After 10 minutes, we realized the DNS servers were restarting and dying and there was actually no way to bring them back up in this state.
We thought we were ready for this. We have the ability to immediately roll back any deployments within a click of a button. And this is when we realized, things were much more complicated than they seemed. We immediately rolled back all updates for the SmartEdge system, but it was already too late.
Both SmartEdge and the deployment systems we use rely on Edge Storage and Bunny CDN to distribute data to the actual DNS servers. On the other hand, we just wiped out most of our global CDN capacity.
While the DNS is auto-healing by itself, every time it attempted to come back, it would try to load the broken deployment and simply crash again. As you can imagine, this essentially prevented the DNS servers from reaching the CDN to download the update and continued in a loop of crashes.
As you can see at 8:35 (15:35), a few servers were still struggling to keep up with requests, but it wasn't with much effect and we dropped the majority of traffic, down to 100Gbit. One lucky point in all of this, we were during our lowest traffic point of the day.
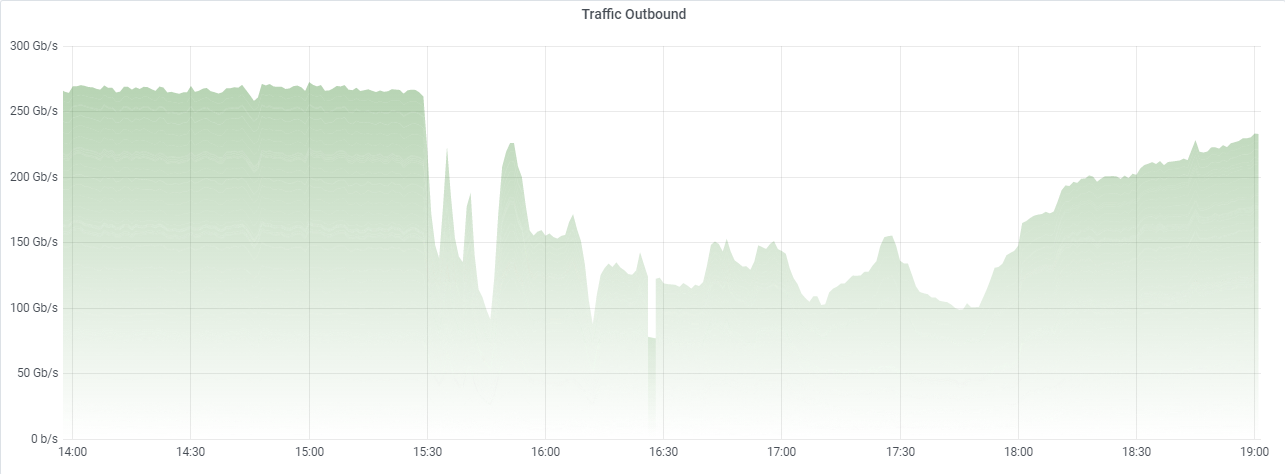
Then things got complicated even more
At 8:45 we came up with a plan. We manually deployed an update that disabled the SmartEdge system to the DNS nodes. Things finally seemed like they were working. Turns out we were very, very wrong. Due to the CDN failure, the DNS servers also ended up downloading corrupted versions of the GeoDNS databases and suddenly, all requests were going into Madrid. As one of our smallest PoPs, it quickly got obliterated.
To make things worse, now 100 servers were restarting in a loop, which started crashing our central API, and even the servers we were able to bring back were now failing to start properly.
It took us some time to realize what was actually going on and after multiple attempts to re-establish the networking, we gave up on the idea.
We were stuck. We desperately needed to get things back online as soon as possible, but we practically managed to kill the whole platform with one simple corrupted file.
Bringing thing things back under control
Since all of our internal distribution was now corrupted and served through the CDN, we had to find an alternative. As a temporary measure, at around 9:40 we decided that if we're sending all requests to one region, we might as well send those to our biggest region. We prepared a routing update that routed all requests through Frankfurt instead.
This was our first success, and a decent portion of traffic was coming back online. But it wasn't a solution. We manually deployed this to a couple of DNS servers, but the rest of the fleet was still sending everything to Madrid, so we needed to act fast.
We decided we screwed up big time, and the only way to get out of this was to stop using our own systems entirely. To do that, we went to work and painstakingly migrated all of our deployment systems and files over to a third party cloud storage service.
At 10:15, we were finally ready. We rewired our deployment system and DNS software to connect through to the new storage and hit Deploy. Traffic was slowly but surely coming back, and at 10:30 we were back in the game. Or so we thought.
Of course, everything was on fire and while we were doing our best to rush this, while also dealing with hundreds of support tickets and keeping everyone properly informed, we made a bunch of typos and mistakes. We knew it's important to stay calm in these situations, but this is easier said than done.
Turns out during our rush to get this fixed, we deployed an incorrect version of the GeoDNS database, so while we re-established the DNS clusters, they were still sending requests to Madrid. We were getting more and more frustrated, but it was time to calm down, double-check everything and make the final deployment.
At 10:45, we did just that. Now connecting everything to a third-party service, we managed to sync up the databases, deploy the newest file sets and get things back online.
We painstakingly watched traffic pick back up for 30 minutes, while making sure things were back online. Our Storage was being pushed to its limits as without the SmartEdge system, we were serving a lot of uncached data. Things finally started stabilizing at 11:00, and bunny.net was back online in recovery mode.
So in short, what went wrong?
We designed all of our systems to work together and rely on each other, including the critical pieces of our internal infrastructure. If you build a bunch of cool infrastructure, you're of course lured into implementing this into as many systems as you can.
Unfortunately, that allowed something as simple as a corrupted file to crash down multiple layers of redundancy with no real way of bringing things back up. It crashed our DNS, it crashed the CDN, it crashed the storage and finally, it crashed the optimizer service.
In fact, the ripple effect even crashed our API and our dashboard as hundreds of servers were being brought back up, which in turn finally also crashed the logging service.
Going forward: Learn and improve!
While we believe this should never have happened in the first place, we are taking it as a valuable lesson learned. We are definitely not perfect, but we are doing our best to get as close as possible. Going forward, the only way to get there is to learn and improve on our mistakes.
First of all, we want to apologize to anyone affected and reassure everyone that we are treating this with the utmost urgency. We had a good run of multiple years without an extensive system-wide failure, and we are determined to make sure this does not happen again anytime soon.
To do this, the first and smallest step will be to phase out the BinaryPack library as a hot-fix and make sure we run a more extensive testing on any third-party libraries we work with in the future.
The bigger problem also became apparent. Building your own infrastructure inside of its own ecosystem can have dire consequences and can fall down like a set of dominos. Amazon proved this in the past, and back then we thought this won't happen to us, and oh how wrong we were.
We are currently planning a complete migration of our internal APIs to a third-party independent service. This means if their system goes down, we lose the ability to do updates, but if our system goes down, we will have the ability to react quickly and reliably without being caught in a loop of collapsing infrastructure.
We will also be investigating how to prevent a single point of failure across multiple clusters caused by a single point of software that is otherwise deemed non-critical. We always try to deploy updates in a granular way using the canary technique, but this caught us off guard since an otherwise non-critical part of the infrastructure presented itself as a critical single point of failure for multiple other clusters at the same time.
Finally, we are making the DNS system itself run a local copy of all backup data with automatic failure detection. This way we can add yet another layer of redundancy and make sure that no matter what happens, systems within bunny.net remain as independent from each other as possible and prevent a ripple effect when something goes wrong.
I would like to share my thanks to the support team that was working tirelessly to keep everyone in the loop and all of our users for bearing with us while we battled through this.
We understand this has been a very stressful situation not only for ourselves, but especially for all of you who rely on us to stay online, so we are making sure we learn and improve from these events and come out more reliable than ever.