













Wildcard CDN Cache Purging Is Here!

Dejan Grofelnik Pelzel

April 22, 2021
There's a joke amongst developers: There are two hard things in computer science, cache invalidation and naming things. We really feel this one.
As a CDN, caching and accelerating content is the core of what we do. We manage hundreds of millions of cached files replicated around the world and have a strict goal to provide close to real-time purging across hundreds of servers across six continents. A simple file that doesn't get deleted on one of the servers can wreck havoc, so we really need to make sure that purging is working completely reliably.
Since the beginning, we provided two simple purging methods, purge by URL and purge by Pull Zone. It was enough for a lot of use-cases, but just wasn't powerful enough for more complex applications. It meant we were limited to sending single purge request calls for each file, which in a complex situation could mean thousands of API calls and a bunch of headaches.
The web is getting more and more sophisticated, and we wanted to provide all the options needed to allow our users to be in complete control of their cache while still providing near-instant invalidation around the world. This is where things get tricky. Let's see why.
Purging A Single File Is Easy
Purging a single file is easy. As long as you know the URL, it's trivial to calculate where the file will be stored and send a delete request accordingly. At bunny.net, we use nginx extensively, so for example, to delete a test zone key for test_zone/300kb.jpg, you would simply calculate an MD5 hash of the key:
0b8ac415aed126018d68859a094d6d62
and then take the last digit combined with the two digits next to that to construct the path to the file:
/2/6d/0b8ac415aed126018d68859a094d6d62
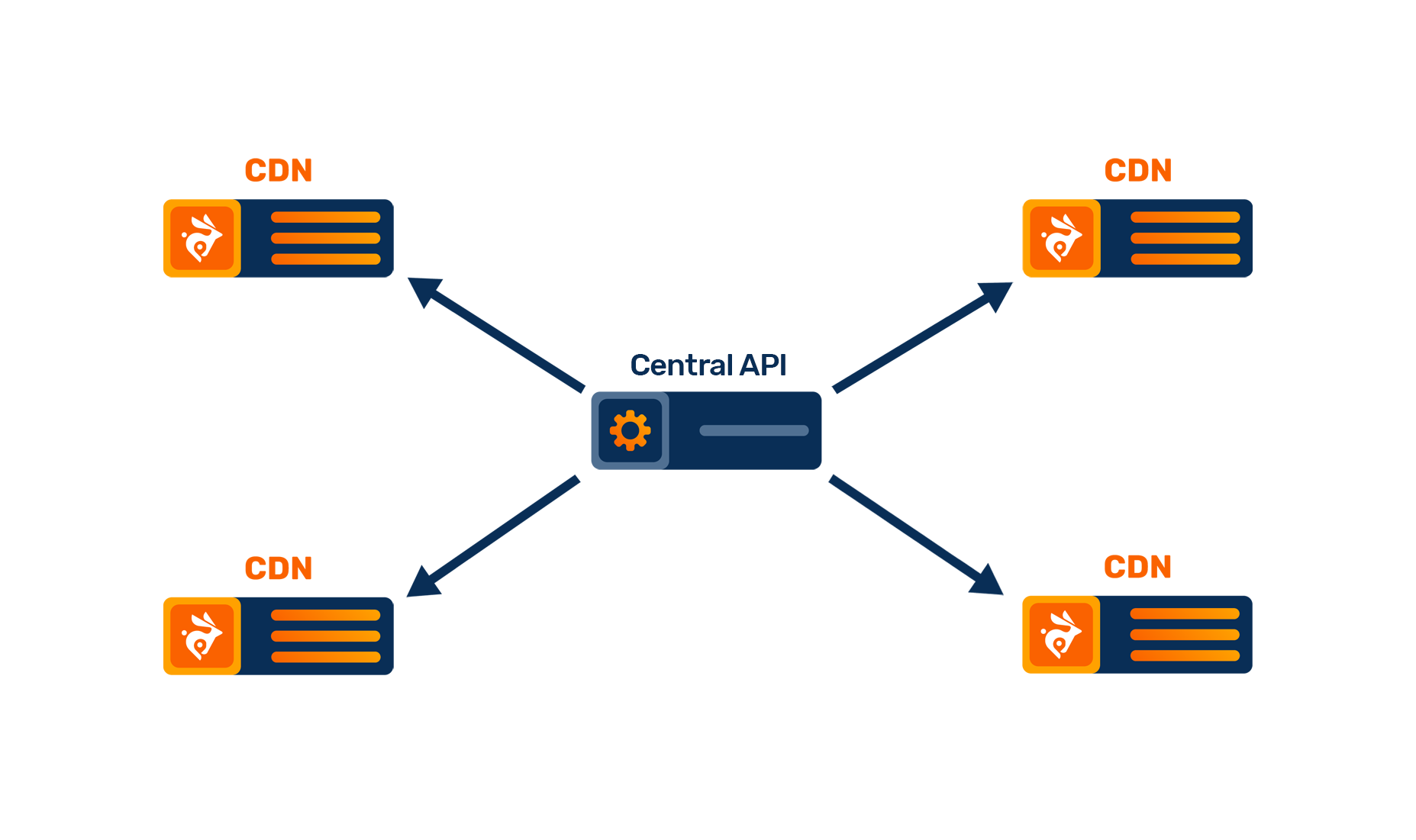
Essentially, until now, every time you fired up a purge request, we sent a request to each of our edge nodes to find and delete the file. This was quick, relatively reliable, and easy to implement, but it just wasn't providing the power we needed.
Purging A Wildcard File Database Is Harder
Scaling from a single URL purge to something more complex gets very different very quickly. We can no longer know which files are stored in which key and we can no longer simply send a simple request to a server to let it know what to delete, especially in a case of a more complex CDN setup with multiple load balancer, storage and caching nodes on each location. As you can see, two very similar URLs produce completely different storage paths:
test_zone/300kb.jpg test_zone/300kb.jpg?v=1
/2/6d/0b8ac415aed126018d68859a094d6d62 /6/a9/0dd9fa59123ab121e2b97a04977469a6
There are some easy ideas, but at our scale, scanning over 100 million files for each purge request was definitely not something we wanted to do. Relying on the nginx cache file manager was also not the best idea because it might or might not know about every file that it hasn't just yet loaded at that point in time. We needed a solution that would use the least amount of resources, provide the best possible reliability and the fastest turnaround possible.
Enter BunnyDB & RabbitMQ
After quite some time of considering the best approach, we were finally happy and confident with a solution. Instead of keeping track of files inside of memory, why not track them in a really fast local database that knows everything about cache. We considered a couple of existing options, but nothing was just quite efficient enough. So when something isn't fast enough, just make your own. We developed an internal database engine (obviously) named BunnyDB that's able to write, read and store millions of operations per second based on the RocksDB storage engine.
This allowed us to build and manage a permanent database of files on each of our servers, giving us a full overview not only on how much data we are storing for each zone, but also when exactly it was accessed and where exactly something is stored without ever touching the files themselves.
The new system allows us to scan through millions of files almost instantly and use powerful wildcard purging to select the files that need to be deleted without ever touching the actual storage disks.
While we were at it, we also wanted to improve our purging control logic. A push to the edge model was alright, but slow, cumbersome and prone to occasionally fail at achieving 100% reliability.
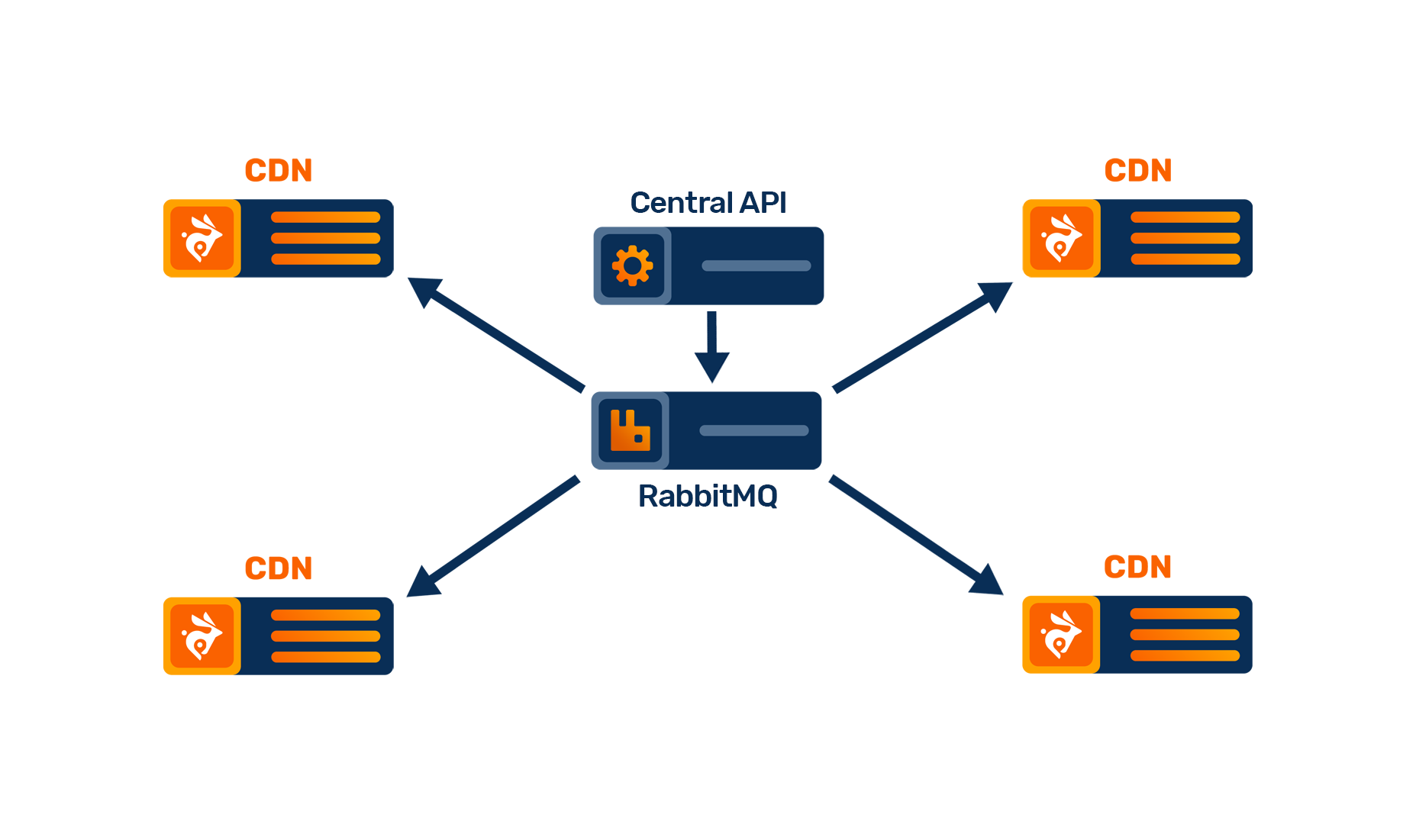
So the obvious choice was to switch to a proper messaging system. We already extensively use RabbitMQ, an incredibly useful piece of software that provides a fast, low latency and high availability messaging.
Any purge request is now passed from the API to the RabbitMQ cluster, which then immediately distributes that to the edge nodes. If an edge node is offline or the connection breaks before a purge is finished, it will simply reconnect and receive the message at a later point in time. Any issues or delays are automatically mitigated by the system itself to make sure every request is 100% reliable and cache is cleared reliably.
From Seconds To Milliseconds
Thanks to how RabbitMQ works, each of the CDN nodes is continuously connected with the central system at all times, allowing us to push the purge times down from seconds into milliseconds. We are able to offer a next-generation caching system with no more purge delays or uncleared cache and allow you to build complex caching on top of Bunny CDN.
We had quite a few requests for wildcard purging over the years, but before we did it, we wanted to do it right. It took some time, but we are finally confident that we have a very good solution that just works.
We are very excited about the update and hope that it allows developers out there to be able to better manage their cache. We are now working to also add tag-based purging to allow even more granular control for situations where the URL itself might not be the best cache marker.
Make sure to follow our blog and social media for more cool updates that we are working on and as always, let us know if you have any feedback or suggestions!
Find out more about Bunny CDN