What is GZIP Compression?
Introduction

GZIP compression is an extremely popular technique used for compressing web content. From web pages and the content referenced therein, GNU Zip’s lossless compression is used by over fifty percent of all websites on the Internet. Despite GZIP’s current popularity, its compression ratio is often worse than Brotli, which offers some improvement over its predecessor. Simply put, GZIP’s adoption is slowly trending downward as websites move to more modern technologies.
That is not to say that GZIP, or other compression formats such as bz2 and xz are going away. They have unique advantages and disadvantages. For example, gzip compressed pages still offer slightly lower decompression times on the client, which could be useful for lower-end devices. Crucially, GZIP is much faster server-side compared to Brotli. Servers and lower-end devices run better with the older compression technique.
Moving onto bz2 and xz, their disadvantages are not their compression ratios (in fact, they are far better than gzip and brotli). The issue is that they take very long to decompress client-side, which could potentially ruin the end-user experience.
Outside of web technologies, GZIP is also commonly used for transferring files. You may have seen the large number of Linux packages that come packaged in “tarballs.” Those files ending in the gz extension were all compressed by the GNU Zip (GZIP) algorithm.
Why do we use web compression?
Latency, or load time, is an important metric because slow websites drive away traffic. Measured in ms, gzip-compressed web content is often an order of magnitude smaller than the original file, which reduces latency.
Using a compression method like gzip or even Brotli tends to reduce latency. Latency to websites that use compression is far lower. In fact, latency to websites tends to be far lower than if they sent uncompressed data. From reduced SSL overhead to file sizes, it is clear why compression is used, even with rising Internet speeds around the world (i.e. time to first render).
How it works
Basically, gzip uses lossless compression. To understand lossless compression, you might consider the computer science concept of Huffman Coding. Basically, gzip identifies repetition in content before it's transmitted. To do this, it uses something called the LZ77 algorithm. Next, a Huffman code (tree) forms and attempts to further compress the data.
Here's an example string:
*"Hello, world! Hello, bunny.net!"*
First, the LZ77 algorithm attempts to link repeated occurrences of words back to a single reference:

(The second reference points back to “hello.”)
Second, gzip’s final processing algorithm (Huffman coding) is applied:
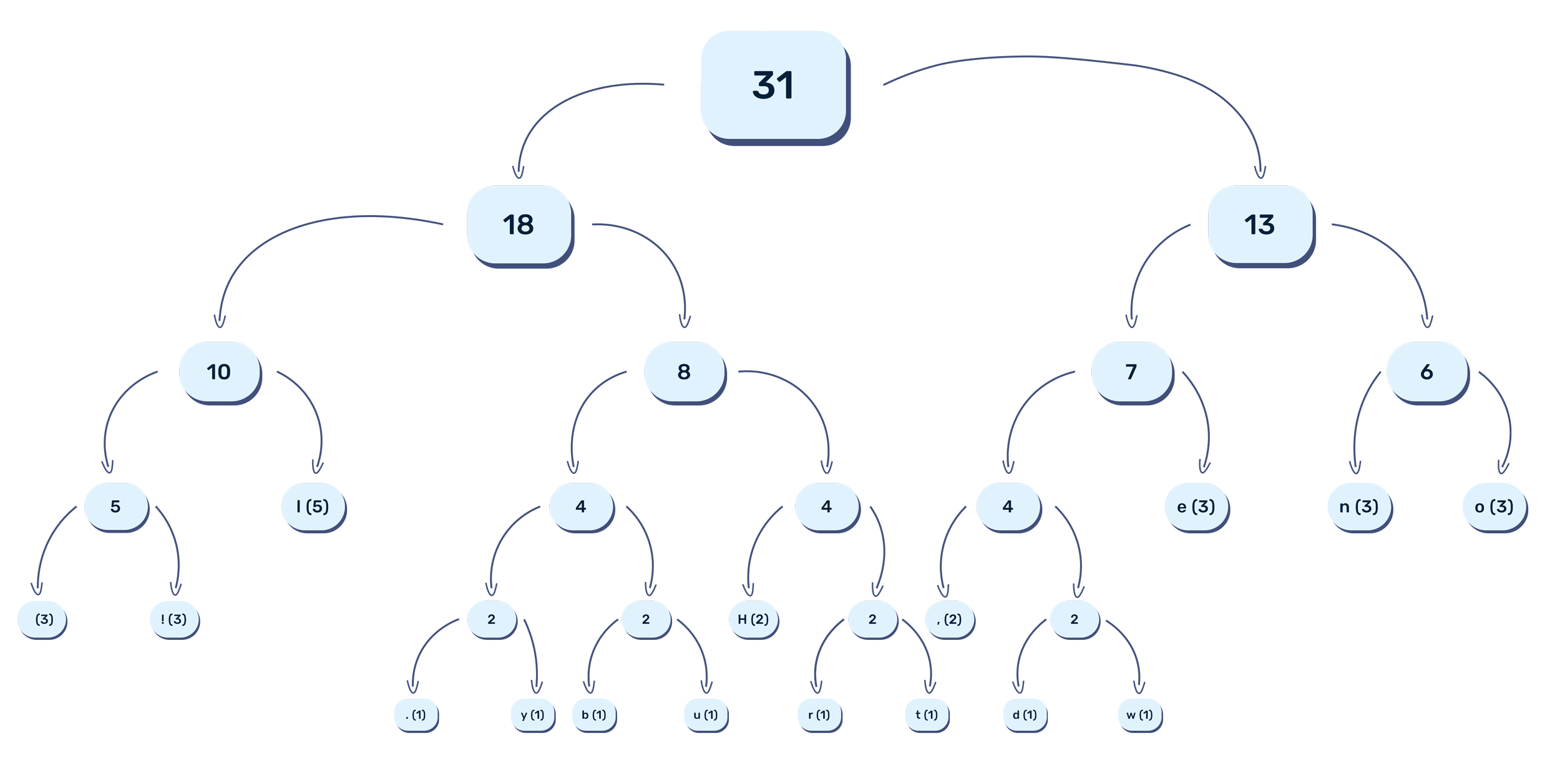
Note: This is a visualization, and individual characters aren't really compressed this way.
With that complete, data can be sent to a client over a binary stream. The client decodes the stream, followed by the tree, and finally, the LZ77-compressed content. The original content (HTML, images, videos, and so on) is ready to be displayed to the end-user.
When to use GZIP
Now that you know how fast GZIP's compression algorithm works, it should be clear that it's designed to run on virtually any client/server while providing an acceptable level of compression for static and dynamic content.
Brotli performs nearly the same as GZIP for client-side decompression, but takes many magnitudes more time to compress server-side, so it's only realistic to use with content that is compressed then cached for later requests.
In essence, GZIP works really well for all types of content, while other compression methods like bz2, xz, and Brotli mostly work well with static content that doesn't change.
Conclusion
While support for GNU Zip is slowly trending downward, it's still really useful. Even with newer compression technologies, the fundamental limitations in lossless compression mean that compression ratios are always a trade-off between server and client-side processing.
